인공지능과
머신러닝의 한 방법으로, 입력 데이터와 그에 상응하는 정답(레이블)을 기반으로 모델을 학습시키는 과정이다. 지도학습에서는 주어진 데이터를 통해 입력과 출력 간의 관계를 파악하고, 새로운 데이터가 주어졌을 때 적절한 출력을 예측하는 모델을 구축한다. 대표적인 알고리즘으로는
선형 회귀,
로지스틱 회귀,
결정 트리,
서포트 벡터 머신(SVM),
신경망 등이 있으며,
이미지 분류,
음성 인식,
자연어 처리 등의 다양한 분야에서 활용된다.
【인용】ChatGPT (2025.3)
정답이 있는 데이터를 활용해 데이터를 학습시키는 것입니다. 입력 값(X data)이 주어지면 입력값에 대한 Label(Y data)를 주어 학습시키며 대표적으로 분류, 회귀 문제가 있습니다.
지도학습 종류
1) 분류(Classification)
분류는 주어진 데이터를 정해진 카테고리(라벨)에 따라 분류하는 문제를 말합니다. darknet의 YOLO, network architecture는 GoodLeNet for image classification을 이용하여 이미지를 분류하고 있습니다. 분류는 맞다, 아니다 등의 이진 분류 문제 또는 사과다 바나나다 포도다 등의 2가지 이상으로 분류하는 다중 분류 문제가 있습니다.
예를 들어 입력 데이터로 메일을 주고 라벨을 스팸메일이다, 아니다 를 주면 모델은 새로운 메일이 들어올 때 이 메일이 스팸인지 아닌지 분류를 할 수 있게 됩니다.
2) 회귀(Regression)
회귀는 어떤 데이터들의 Feature를 기준으로, 연속된 값(그래프)을 예측하는 문제로 주로 어떤 패턴이나 트렌드, 경향을 예측할 때 사용됩니다. 즉 답이 분류 처럼 1, 0이렇게 딱 떨어지는 것이 아니고 어떤 수나 실수로 예측될 수 있습니다.
예를 들어 서울에 있는 20평대 아파트 집값 가격, 30평대 아파트 가격, 지방의 20평대 아파트 가격등을 입력데이터로 주고 결과를 주면, 어떤 지역의 30평대 아파트 가격이 어느정도 인지 예측할 수 있게 됩니다.
※ Feature
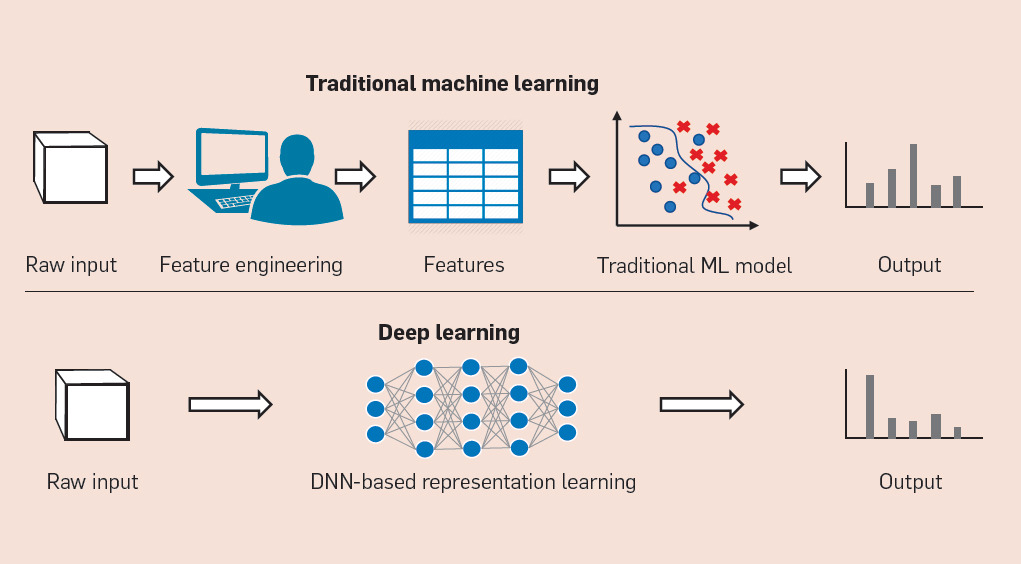
머신러닝은 어떤 데이터를 분류하거나, 값을 예측(회귀)하는 것입니다. 이렇게 데이터의 값을 잘 예측하기 위한 데이터의 특징들을 머신러닝/딥러닝에서는 "Feature"라고 부르며, 지도, 비지도, 강화학습 모두 적절한 feature를 잘 정의하는 것이 핵심입니다. 엑셀에서 attribute(column)라고 불려지던 것을 머신러닝에서는 통계학의 영향으로 feature라고 부릅니다. 과거에 딥러닝 이전의 머신러닝에서는 Raw데이터를 피처 엔지니어가 직접 적절한 피처를 만들고, 머신러닝 모델의 결과로 아웃풋을 냈었는데, 딥러닝 이후로 Raw데이터를 딥러닝 모델에 넣어주면 모델이 알아서 feature를 알아내고 아웃풋을 내는 형식으로 발전하게 되었습니다. (머신러닝 모델이 피처를 알아서 찾아준다고 하여도 여전히 전처리 작업은 중요합니다.)
예를 들어 고양이, 강아지 사진은 분류한다고 하면 고양이는 귀가 뾰족하다 거나 눈코입의 위치, 무늬 등이 피처가 됩니다. 키와 성별을 주고 몸무게를 예측한다고 하면 키와 성별이 피처가 됩니다.
Feature는 Label, Class, Target, Response, Dependent variable 등으로 불려집니다.
【출처】https://ebbnflow.tistory.com/165 [삶은 확률의 구름:티스토리] (2025.3)